
【协会大规模专家平行技术解码】双流并行实现
发布时间:2025-04-18 09:02
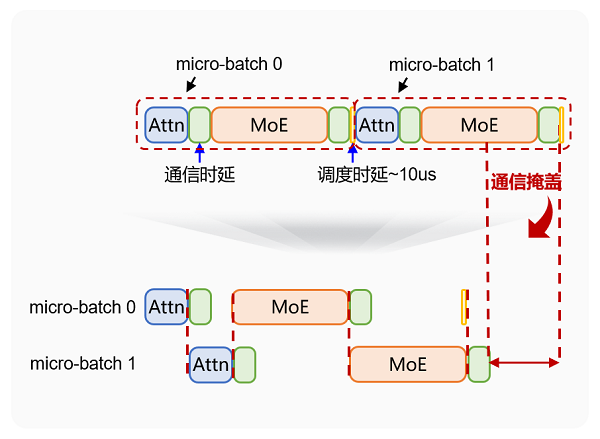 Ascend并行专家的伟大方法的主要思想是,在许多子节点专家中,部署Shard的许多子专家模块中的大型专家模型(例如具有1000亿参数的MOE模型),并将其专用于不同的计算节点以独立执行。在这个问题中,我们将重点关注大规模专家在平行通信方面的攀登:通过技术变革的双流式流程减少沟通开销。 Delaying Moe's scenario communication and the path of optimization of large experts in parallel in parallel approach puts higher requirements for delaying cross-node communication, which is common to AI clusters: first, with exponential growth of model parameter models, the traditional ones youde of communication (such as Alltoall) faces serious problems with bandwidth competition, especially in clusters at the upper level of kilocard, the delay in communication will significantly increASE随着节点的数量增加;其次,将不对称资源调整到异质计算环境(例如不均匀的计算卡和各种存储器带宽)使得很难平衡通信的负载,从而产生了“ Buntot效应”;此外,MOE现代体系结构独有的专家选择的动态机制已将通信方式从静态转变为动态 - 新的,进一步加剧了适应传统通信解决方案的难度。上升MOE双流并行优化01 Prefillmicro Batch双流并行性:计算和通信涵盖Bawand One,将绩效提高了20%+LLM模型处于构想阶段。由于输入长度(SEQLEN),其性能主要受到计算时间的限制,因为批次化增加,时间计算的时间会增加。同时,预填充阶段的通信数据量为批处理* seqlen* HIDDENSIZE。随着批处理的长度和订单的增加,通信数据的数量也大大增加,从而导致通信时间提供了总时间的20%-30%。在这方面,Ascend Cann已实现了显着的优化,将预填充批量分为许多较小的微匹配。如下图所示,通过保存微匹配之间的计算和通信过程,通信时间是完全掩盖的capeg,计算需要很长时间,从而获得了20%+的性能益处。照片1Prefill Micro Batch双流平行性02重量预取双流并行性:内存获取和通信并行性,在受孕的解码阶段将绩效提高10%+,重量(重量)需要很长时间才能加载。主要原因是重量通常需要访问高带宽(HBM)内存,从而导致大型缓存带宽开销。为了解决这个问题,使用较大的容量和较高的bandwiAscend 910系列L2Cache层的DTH性能,将重量预拿到重量并将其存储在L2Cache中,从而可以实现通信和重量负载,从而促进了随后的立方体操作,并显着减少了重量加载时间,改善了网络性能,整个网络性能增加了10%+。图2权重预取双流并行[使用方法]最新版本的Ascend Cann中实现了顶部爆发功能。欢迎每个人在Mindie中使用和经验。有关安装CANN套餐的过程,请参阅社区文件:https://www.hiascend.com/document/detail/detail/zh/canncommunityeditation/81rc1alpha001/softwareinst/softwareinst/softwareinst/instg/instg/instg/instg/instg_000000000000.html?模型通信。我们将在上升硬件中充分利用多核并发功能,以加快发行版,同时提供通信Activities;同时,我们探讨了通信运营商和其他计算运营商的良好元素通信集成,减少或覆盖启动和交付的开销,并为更多的客户和合作伙伴提供更强的技术能力。
Ascend并行专家的伟大方法的主要思想是,在许多子节点专家中,部署Shard的许多子专家模块中的大型专家模型(例如具有1000亿参数的MOE模型),并将其专用于不同的计算节点以独立执行。在这个问题中,我们将重点关注大规模专家在平行通信方面的攀登:通过技术变革的双流式流程减少沟通开销。 Delaying Moe's scenario communication and the path of optimization of large experts in parallel in parallel approach puts higher requirements for delaying cross-node communication, which is common to AI clusters: first, with exponential growth of model parameter models, the traditional ones youde of communication (such as Alltoall) faces serious problems with bandwidth competition, especially in clusters at the upper level of kilocard, the delay in communication will significantly increASE随着节点的数量增加;其次,将不对称资源调整到异质计算环境(例如不均匀的计算卡和各种存储器带宽)使得很难平衡通信的负载,从而产生了“ Buntot效应”;此外,MOE现代体系结构独有的专家选择的动态机制已将通信方式从静态转变为动态 - 新的,进一步加剧了适应传统通信解决方案的难度。上升MOE双流并行优化01 Prefillmicro Batch双流并行性:计算和通信涵盖Bawand One,将绩效提高了20%+LLM模型处于构想阶段。由于输入长度(SEQLEN),其性能主要受到计算时间的限制,因为批次化增加,时间计算的时间会增加。同时,预填充阶段的通信数据量为批处理* seqlen* HIDDENSIZE。随着批处理的长度和订单的增加,通信数据的数量也大大增加,从而导致通信时间提供了总时间的20%-30%。在这方面,Ascend Cann已实现了显着的优化,将预填充批量分为许多较小的微匹配。如下图所示,通过保存微匹配之间的计算和通信过程,通信时间是完全掩盖的capeg,计算需要很长时间,从而获得了20%+的性能益处。照片1Prefill Micro Batch双流平行性02重量预取双流并行性:内存获取和通信并行性,在受孕的解码阶段将绩效提高10%+,重量(重量)需要很长时间才能加载。主要原因是重量通常需要访问高带宽(HBM)内存,从而导致大型缓存带宽开销。为了解决这个问题,使用较大的容量和较高的bandwiAscend 910系列L2Cache层的DTH性能,将重量预拿到重量并将其存储在L2Cache中,从而可以实现通信和重量负载,从而促进了随后的立方体操作,并显着减少了重量加载时间,改善了网络性能,整个网络性能增加了10%+。图2权重预取双流并行[使用方法]最新版本的Ascend Cann中实现了顶部爆发功能。欢迎每个人在Mindie中使用和经验。有关安装CANN套餐的过程,请参阅社区文件:https://www.hiascend.com/document/detail/detail/zh/canncommunityeditation/81rc1alpha001/softwareinst/softwareinst/softwareinst/instg/instg/instg/instg/instg_000000000000.html?模型通信。我们将在上升硬件中充分利用多核并发功能,以加快发行版,同时提供通信Activities;同时,我们探讨了通信运营商和其他计算运营商的良好元素通信集成,减少或覆盖启动和交付的开销,并为更多的客户和合作伙伴提供更强的技术能力。 下一篇:没有了